Inference and the KV Cache
This section assumes a very basic understanding of the GPU programming model, a brief refresher of which is at Appendix: GPU Hardware .
Inference Execution
At the simplest level, inference takes a token or group of tokens from the user and feeds those tokens through the model to get the next token in the sequence, a process that is iteratively repeated until termination.
First, the user input is processed and the internal state of the transformer is set up. This is called the prompt or the prefill phase; this is followed by the generation of new tokens which is called the autoregressive or decode phase. In the prefill phase, the entire input is available at the same time and can be processed in parallel, making it a primarily compute-bound operation on the GPU. In the autoregressive phase, each subsequent generation requires the previously generated token, making it a sequential process. This requires accessing a lot of memory (the entire prior sequence), but has low compute requirements.
Execution is transferred between the CPU and the GPU during inference, with the CPU primarily acting as a controller and setting up memory and operations for the GPU to execute. The CPU explicitly allocates memory and copies the model parameters into the GPU’s main memory (High Bandwidth Memory or HBM) using the device API (cudaMalloc/Memcpy or hipMalloc/Memcpy in CUDA and ROCm) and selects a kernel to execute on the GPU. The CPU then either waits for an interrupt when execution of the kernel is complete or polls the GPU for completion, depending on the mode of operation.
Assuming inference which handles a single request at a time, the CPU sets up GPU memory with the prompt for the request (the model is assumed to always be loaded into GPU memory), and requests execution of the kernels forming the autoregressive phase on the GPU cores. The kernels generate one or more new tokens before returning execution back to the CPU, which checks for termination conditions. If the termination condition has not been reached, the CPU restarts the kernels to generate more tokens.
In reality, no inference runtime is serialized and runs only a single request at a time. There are a number of batching, scheduling, and paging decisions which go into handling request concurrency, which are discussed at Batching, Scheduling, and Paging .
The KV Cache
The prefill and the autoregressive phases are not actually different in the kind of operations that they execute, but only differ in granularity: both of them take a context (the prompt in the case of prefill, and the prompt and all the generated tokens in the case of the autoregressive phase) and pass it through several transformer (attention and feed-forward) layers to generate a new token.
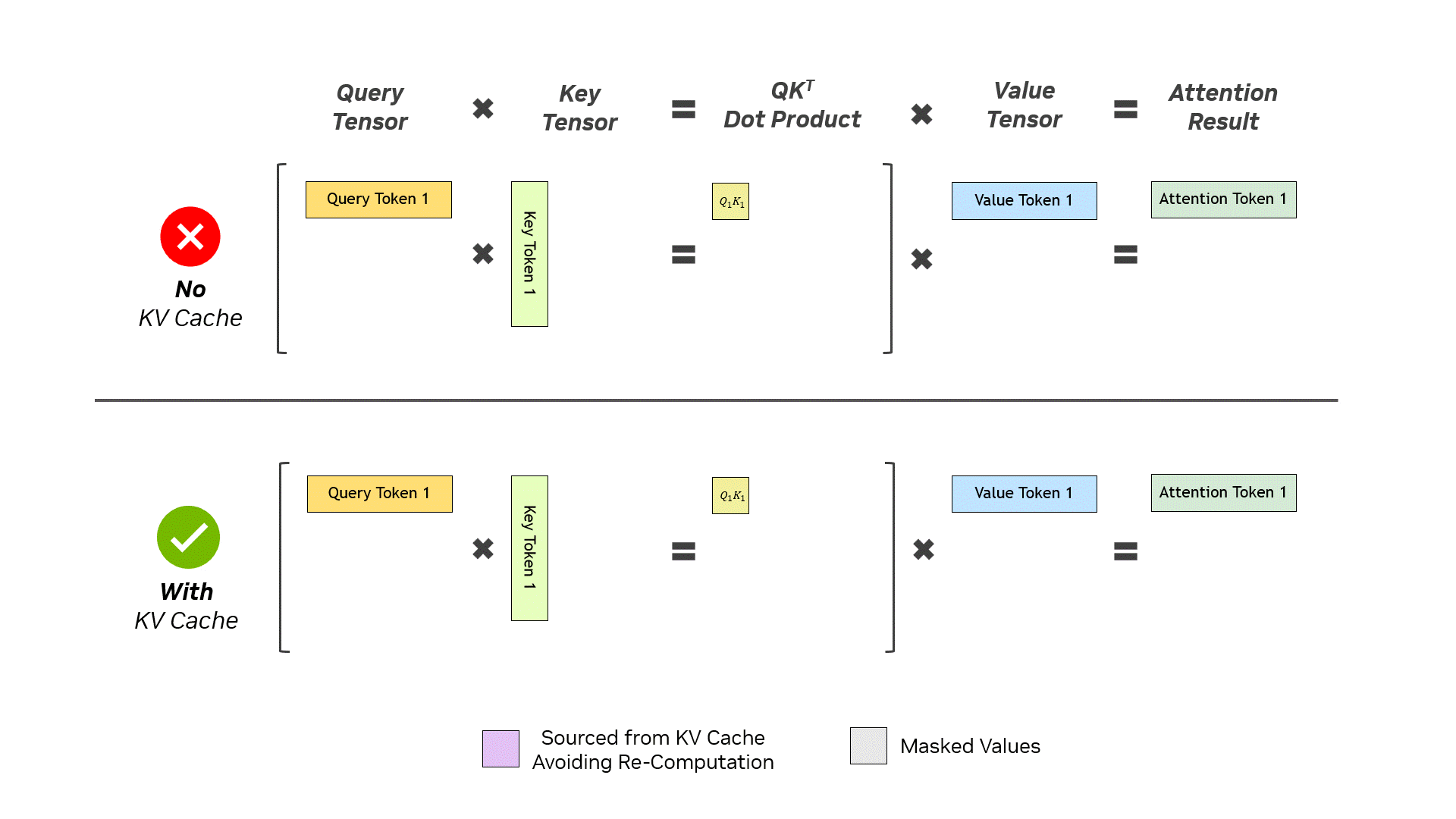
Every head of every attention block in every layer of the transformer takes the input context and generates Q, K, and V matrices from it, each of which are sized with a row for every token in the input. These matrices are then multiplied making this step quadratic in complexity. Assume an input prompt of 3 tokens, the Q, K, and V matrices have 3 rows and are multiplied to generate a single token. This is then appended to each of the matrices, making them have 4 rows, which are once again multiplied. If one looks at the $Q \times K^T$ operation, the top left hand corner of the resulting matrix is identical to the previous iteration with the compute being repeated unnecessarily—the only required new compute is that the Q vector of the new token has to be multiplied by the entire $K^T$ matrix and then the V matrix (this only works because causal masking prevents future tokens from affecting previously generated ones).
(A visual illustration of the KV Cache from NVIDIA)
The KV cache caches the previous K and V matrices: during the attention phase, these are retrieved and multiplied with the new Q vector to calculate the attention scores. The newly computed K and V vectors are then appended to the K and V matrices and the updated matrices are stored in the KV cache. The KV cache converts the quadratic complexity of attention, for every step of the token generation, into linear complexity by trading memory for compute and obviating the need to recompute the old K and V matrices. Because the KV matrices are being cached for every request in every head in every layer, techniques such as multi/group-query attention (MQA/GQA) or multi-head latent attention (MLA) substantially reduce the size of the KV cache during inference.
The KV cache grows with the length of the context and can grow unboundedly large: to prevent this, there usually is a maximum allowed size for the KV cache and tokens are evicted as the context grows beyond that. Simple eviction strategies, such as sliding windows, fail spectacularly the moment the KV cache exceeds the maximum size and the initial tokens are evicted.
This collapse in performance holds even when the initial tokens have little semantic information and is a function of how the attention scores are calculated; even when all the tokens in a batch have little semantic importance the attention scores, being a probability distribution, must sum up to 1.0 and the process defaults to directing importance towards the first tokens (called attention sinks). When these tokens are evicted, it shifts the attention distribution dramatically which causes model performance to drop. More sophisticated eviction techniques preserve model performance by always preserving the first few tokens or by balancing token recency with their attention scores.
The KV cache for each request is unique and independent and can immediately be discarded to free GPU memory once the request is completed. More advanced workloads can benefit from preserving the KV cache beyond the lifetime of a single request for performance reasons. This is discussed further in KV Cache Management and Offload .